Tutorial: Ink Detection
Last updated: July 10, 2026
Ink detection is the last step of the pipeline: taking the flattened surface of a papyrus sheet (segmented from the 3D X-ray scan) and identifying where the ink is, so that the text can be read.
This is where one of the core difficulties of the Herculaneum Papyri comes in: the carbon ink and the carbonized papyrus have almost the same density, so in an X-ray scan the ink is nearly invisible to the naked eye. The problem is easiest to see on a detached fragment, where the writing is exposed and we can photograph it directly: in a color photograph the letters are faint, in 1000 nm infrared they are crisp and legible, but in the X-ray CT scan the ink contrast almost completely disappears.



So why scan with X-rays at all? Because visible and infrared light can't see inside a rolled scroll — they don't penetrate the papyrus. X-ray CT does: it images the interior of an intact scroll at high resolution, but, as the fragment above shows, at the cost of the visible ink contrast. Ink detection exists to win that contrast back computationally.
Not all of that contrast is lost, though. What does the surviving signal look like? In PHerc. Paris 4 in particular, ink can sit as a thin layer on the papyrus surface, and on the flattened surface volume it often shows up as a crackle — a texture like cracked mud, raised slightly above the papyrus. Crackle is one of several surface-morphology cues that can betray ink; on other scrolls the signal is more subtle and heterogeneous, and may instead depend on fine texture, local roughness, deposits, or deformation.
This crackle is what first revealed letters inside an intact scroll, spotted by eye in raw surface volumes. But it is the exception. Most scrolls show nothing so legible, so models trained on known ink learn to pick up traces the eye can't name. Several scrolls are still waiting for their first letters, and each is worth $50,000 in the open First Letters Prizes. Finding them takes a searching eye and a model's predictions. By the end of this tutorial you'll have both — and maybe you'll be the first person to read those words in 2,000 years.
How ink detection works
An ink detection model does signal recovery, not reading. The model looks at a small local patch of the surface volume (the stack of slices sampled around the papyrus surface) and predicts, for each pixel, the probability that there is ink at that location. Stitching these predictions together produces an image of the segment where the writing becomes visible to a human reader.
We train the model by picking a pixel in a binary label image, sampling a subvolume around the same coordinates from the surface volume, and backpropagating the known label to update the model weights:
We can then use the model to predict what a label image would have looked like, on data it has never seen:
Where do the labels come from? The first ink labels came from detached fragments, where the exposed writing can be photographed in infrared and aligned with the surface volume. For the intact scrolls, labels are made iteratively: an existing model is run on a scroll segment, a human inspects the predictions, labels the regions where letter strokes are clearly visible, and the model is retrained on the enlarged dataset. Repeating this loop is how ink detection has improved from isolated letters to entire scrolls.
This process recently achieved the complete virtual unwrapping and reading of PHerc. 1667: the first Herculaneum scroll to be fully digitally unrolled and read without physical opening. The methods, including the labeling and validation methodology this tutorial is based on, are described in detail in the paper.
Because the labels come from model predictions, the process is designed to avoid reinforcing the model's own errors:
- The model only sees small local patches — smaller than a full letter — so it cannot learn to "draw" plausible letterforms.
- Labeling is conservative: only regions where strokes are clearly and repeatably visible get labeled.
- Validation regions are held out, so you can measure whether the model generalizes.
- Final readings are always reviewed by papyrologists. Machine output is never treated as a substitute for reading.
Now let's train a model. The rest of this tutorial is hands-on: you will set up the training pipeline, download a labeled dataset, train an ink detection model, and run inference on a scroll segment. It is written for Linux (Windows users are advised to use WSL2) and assumes an NVIDIA GPU with a working CUDA installation.
The dataset
The tutorial uses the ink-labels dataset, which lives in the scrollprize/datasets storage bucket on Hugging Face, organized by scroll. The full dataset is hundreds of GB, so the whole tutorial runs end-to-end on one segment of PHerc. Paris 4 (Scroll 1) — about 25 GB:
uvx --from huggingface_hub hf buckets sync \
hf://buckets/scrollprize/datasets/ink/phercparis4/w00_20231016151002 \
./ink-dataset/phercparis4/w00_20231016151002
hf buckets sync works like rsync: re-running it resumes interrupted downloads and only transfers what changed. If you hit rate limits, create a free account, generate a read token under Settings → Access Tokens, and either run uvx --from huggingface_hub hf auth login once or set HF_TOKEN=hf_... in your environment.
Each segment is a folder in the layout the training pipeline expects, containing the surface geometry (.tifxyz), the surface volume, and the labels:
ink-dataset/phercparis4/
└── w00_20231016151002/
├── x.tif # surface geometry: 3D coordinates
├── y.tif # of every surface pixel
├── z.tif
├── meta.json
├── w00_20231016151002.zarr # surface volume (image data)
├── w00_20231016151002_inklabels.zarr # binary ink labels
├── w00_20231016151002_inklabels.tif # (and the editable TIFF original)
├── w00_20231016151002_supervision_mask.zarr # where the labels are trustworthy
└── w00_20231016151002_supervision_mask.tif
The label files work together, and understanding them is the key to the whole pipeline:
- Ink labels — a binary image aligned with the segment: white where there is ink, black where there is not.
- Supervision mask — marks the regions where the labels can be trusted. Only pixels inside the supervision mask contribute to the training loss: white pixels there are positive (ink) examples, black pixels are negative (no ink) examples. Everything outside the mask is ignored, so unlabeled or ambiguous areas don't teach the model anything wrong.
- Validation mask — some segments also have a
<segment>_validation_mask.zarr: a held-out region, labeled the same way as the rest, but excluded from training and used only to measure the model's accuracy. A segment without one (like the tutorial segment) still trains — you just get no validation metrics for it.
Here is what that looks like on a crop of the tutorial segment. First, the ink labels: strokes that a human labeler could clearly and repeatably see, painted on top of the surface volume:

The supervision mask covers those strokes plus the clean papyrus around them. Those background pixels are the negative examples, and they matter just as much as the ink:

The filename prefixes must exactly match the segment folder name: a segment folder named w00_20231016151002 must contain w00_20231016151002_inklabels.zarr, w00_20231016151002_supervision_mask.zarr, etc. The pipeline discovers segments and their labels by these names.
Setting up the pipeline
The ink detection pipeline lives in the villa repository, under ink-detection/. It uses uv to manage its Python environment.
git clone https://github.com/ScrollPrize/villa.git
cd villa/ink-detection
git checkout merge-ink-pipelines
uv sync
uv sync creates a virtual environment and installs the exact locked dependencies (PyTorch, zarr, and friends). Verify that PyTorch sees your GPU:
uv run python -c "import torch; print(torch.__version__, '| cuda:', torch.cuda.is_available())"
Training
Training runs are configured with a single JSON file. Create configs/ink_tutorial.json (the configs folder doesn't exist yet; create it too), pointing segments_path at the folder containing your downloaded segments:
{
"out_dir": "runs/ink_tutorial",
"seed": 42,
"mode": "flat",
"model_type": "vesuvius_unet",
"in_channels": 1,
"model_config": { "autoconfigure": true, "z_projection_mode": "max" },
"targets": { "ink": { "out_channels": 1, "activation": "none", "z_projection_mode": "max" } },
"patch_size": [64, 256, 256],
"patch_overlap": 0.5,
"patch_min_labeled_coverage": 0.05,
"batch_size": 2,
"num_iterations": 20000,
"learning_rate": 0.01,
"mixed_precision": "fp16",
"dataloader_workers": 4,
"val_every": 500,
"save_every": 1000,
"datasets": [
{
"segments_path": "/path/to/ink-dataset/phercparis4",
"volume_scale": "0"
}
]
}
The important options:
mode: "flat"trains directly on the pre-rendered surface volume zarrs. This is the standard 2.5D setup: the model takes a 3D patch of the surface volume as input and predicts a 2D ink image as output. Nothing is rendered on the fly. (The pipeline also has native 3D modes —full_3d,full_3d_single_wrap— which instead sample patches on the fly from the original scroll volume using the.tifxyzcoordinates; they get their own section below.)z_projection_mode: "max"is what makes it 2.5D — the network processes the patch in 3D, then the ink head collapses the depth axis with a max-projection to produce the 2D prediction. (mean,logsumexp, andlearned_mlpare alternative projections to experiment with.)patch_sizeis the[z, y, x]size of the patches sampled around the surface: 64 slices deep, 256×256 pixels across. Each dimension must be divisible by the network's pooling factors — the trainer prints the required factors and adjusts or complains if they don't match.patch_overlap: 0.5means training patches are sampled with a half-patch stride across each segment.patch_min_labeled_coverage: 0.05skips training patches whose ink labels cover less than 5% of the patch, so training focuses on labeled regions.val_everycontrols how often validation metrics are computed on the validation-mask regions, andsave_everyhow often checkpoints are written.segments_pathpoints at the folder of segments, not a single segment — the trainer picks up every valid segment it finds there, so the same config keeps working as you add more. One segment is enough for a real first model.
Then start training:
uv run python -m koine_machines.training.train configs/ink_tutorial.json
The trainer discovers your segments, finds all training patches inside the supervision masks (excluding the validation regions), and starts training. Patch discovery can take a while on large datasets; the result is cached as a JSON file in out_dir, keyed by patch size, overlap, and label version, so re-runs with the same settings skip it. With this config, the full 20,000-iteration run takes about an hour and a half on a single H100. While it runs you will see the loss printed to the console, and in runs/ink_tutorial/ you will find:
ckpt_001000.pth,ckpt_002000.pth, ... — checkpoints, saved everysave_everyiterations.train_previews/(andval_previews/, when there is a validation set) — periodic image previews of the model's predictions next to the labels. Watching the previews go from noise to letter strokes is the most satisfying part of the process.
If your dataset includes segments with validation masks, the model is also evaluated on those held-out regions at each validation step, reporting balanced accuracy — how well it detects ink in areas it was never trained on. If training loss keeps dropping while validation accuracy stalls, the model is starting to overfit your labels. (The tutorial segment has no validation mask, so this first run reports training loss only.) You can stop training at any time with ctrl+c and use the most recently saved checkpoint.
If you run out of GPU memory, reduce batch_size to 1, or reduce the patch_size to [64, 128, 128]. For multi-GPU training, launch through Accelerate instead: uv run accelerate launch --num_processes 2 --module koine_machines.training.train configs/ink_tutorial.json.
To log metrics and previews to Weights & Biases, add "wandb_project": "ink-detection" and "wandb_entity": "your-username" to the config and run uv run wandb login once.
Inference
To run your trained model on the same segment and produce an ink prediction image:
uv run python -m koine_machines.inference.infer \
/path/to/ink-dataset/phercparis4/w00_20231016151002/w00_20231016151002.zarr \
runs/ink_tutorial/ckpt_020000.pth \
predictions/w00_20231016151002.tif \
--batch-size 4
The three positional arguments are the segment's surface volume, the checkpoint (here the last one written by the 20,000-iteration run above), and the output path. The model slides across the whole segment in overlapping windows, blends the overlapping predictions, and writes a grayscale TIFF where each pixel's brightness (0–255) is the predicted probability of ink. Expect this to take on the order of an hour on a single GPU for a full segment. Open the result in any image viewer, and if all went well, you'll see letters, including outside the regions you had labels for.
For a faster first look, pass --mask-path region.tif — a grayscale TIFF the size of the segment where nonzero pixels mark the region to predict — to limit inference to an area of interest.
Useful options:
--gpus 0,1— run on multiple GPUs.--tta-mirror— average predictions over mirrored versions of each patch (slower, slightly better).--layer-start/--layer-end— restrict which depth layers of the surface volume are used.
Here is the result on the tutorial segment — the model's prediction in white, with the ink labels it was trained on overlaid in red:

Native 3D: training and inference
Everything above is the 2.5D path: pre-rendered surface volume zarr in, 2D ink image out. The pipeline can also work natively in 3D, skipping the rendered surface volume entirely: for every training patch it uses the .tifxyz coordinates to find where the segment passes through the original scroll volume, samples a 3D crop there on the fly, and projects the 2D labels into the crop around the surface. The model then predicts ink directly in scroll space.
Two native 3D modes exist. full_3d trains on the raw crops; full_3d_single_wrap additionally feeds the model a second input channel marking which voxels belong to this segment's own wrap of papyrus, so the model isn't confused where neighboring wraps pass through the same crop — this is the mode to prefer.
Native 3D training
Create configs/ink_full3d.json. It is the same shape as the 2.5D config with a few changes: the mode, no z-projection (the prediction stays 3D), a full_3d block controlling the label projection, an on-disk cache for the streamed volume chunks, and a dataset entry that gains a volume_path pointing at the original scroll volume and trains at pyramid level 2 instead of full resolution:
{
"out_dir": "runs/ink_full3d",
"seed": 42,
"mode": "full_3d_single_wrap",
"model_type": "vesuvius_unet",
"model_config": { "autoconfigure": true },
"targets": { "ink": { "out_channels": 1, "activation": "none" } },
"patch_size": [80, 128, 128],
"patch_overlap": 0.5,
"patch_min_labeled_coverage": 0.05,
"full_3d": {
"label_projection_half_thickness": 16,
"background_projection_half_thickness": 16
},
"batch_size": 8,
"num_iterations": 20000,
"learning_rate": 0.01,
"mixed_precision": "fp16",
"dataloader_workers": 8,
"prefetch_factor": 2,
"volume_cache_dir": "volume_cache",
"volume_cache_max_gb": 120,
"val_every": 500,
"save_every": 1000,
"datasets": [
{
"segments_path": "/path/to/ink-dataset/phercparis4",
"volume_path": "s3://vesuvius-challenge-open-data/PHercParis4/volumes/20260411134726-2.400um-0.2m-78keV-masked.zarr/",
"volume_scale": "2"
}
]
}
volume_pathis where the 3D crops come from. The publicvesuvius-challenge-open-dataS3 bucket is read anonymously — no AWS account needed. You can also download the volume locally (or just the chunks your segments touch, withkoine_machines.preprocessing.download_required_zarr_chunks) and pointvolume_pathat the local copy instead.volume_scale: "2"samples the crops from level 2 of the volume pyramid — 4× downsampled in each axis. That's enough for the tutorial; training at native resolution ("0") can bring further gains, at the cost of a much longer run. Distances in the config are always given in full-resolution voxels regardless ofvolume_scale— the pipeline converts them to the trained level internally.- The
full_3dblock sets how far above and below the surface the 2D ink labels and supervision mask are projected into the crop, in full-resolution voxels (here ±16, so ±4 voxels at level 2). volume_cache_direnables an on-disk LRU cache (capped atvolume_cache_max_gb) for the chunks streamed fromvolume_path: each chunk is downloaded once and re-read from local disk afterwards, which makes both re-runs and inference (which shares the cache) much faster.- There is no
in_channels— the native 3D modes set it automatically before model construction.full_3d_single_wrapuses two input channels (the volume image and the reconstructed surface mask), as doesnormal_pooled_3d; plainfull_3duses one.
Training starts the same way:
uv run python -m koine_machines.training.train configs/ink_full3d.json
This run — 20,000 iterations at batch size 8 — takes about eight hours on an H100 with the tutorial segment and uses about 17 GB of VRAM.
You don't have to wait eight hours to see results. Checkpoints land in the run folder every save_every iterations, so while training continues you can run the inference command below on an intermediate checkpoint, say ckpt_005000.pth, and watch the predictions improve from checkpoint to checkpoint.
Native 3D inference
Native 3D checkpoints use a different inference script, koine_machines.inference.infer_full3d_tifxyz, which samples patches the same way and writes a sparse 3D OME-Zarr prediction volume instead of a 2D image.
For inference the segment folder must contain a volume_source.txt — a single line with the path or URL of the original scroll volume:
echo "s3://vesuvius-challenge-open-data/PHercParis4/volumes/20260411134726-2.400um-0.2m-78keV-masked.zarr/" \
> /path/to/ink-dataset/phercparis4/w00_20231016151002/volume_source.txt
Then, with your native-3D checkpoint:
uv run python -m koine_machines.inference.infer_full3d_tifxyz \
/path/to/ink-dataset/phercparis4/w00_20231016151002 \
runs/ink_full3d/ckpt_020000.pth \
predictions/w00_20231016151002_ink.ome.zarr \
--resolution 2 \
--write-region occupied --chunk-halo 0 \
--batch-size 8 --num-workers 8 \
--cache-dir volume_cache --cache-max-gb 120 \
--overwrite
--resolution 2must match thevolume_scalethe checkpoint was trained at.- At
--batch-size 8, inference uses about 6.5 GB of VRAM. --num-workers 8prepares patches in parallel worker processes, keeping the GPU supplied.--write-region occupied --chunk-halo 0restricts the output to just the chunks that actually contain surface points, which is much faster than the default (which also writes a halo of neighboring chunks). Even at level 2 a single segment plans thousands of patches (hundreds of thousands at full resolution) — add--plan-onlyto preview the chunk/patch plan first, and only launch the full command when the printed patch count fits your compute budget.- For
full_3d_single_wrapcheckpoints, the script reconstructs the surface-mask input channel from the.tifxyzgeometry automatically.
The result is an ink prediction in scroll coordinates rather than a flattened image:
To read it, render it through the segment geometry with VC3D's vc_render_tifxyz — the same tool that renders surface volumes from the scroll, just pointed at the prediction volume instead. You'll need a VC3D build on your PATH; see the VC3D tutorial's installation instructions.
vc_render_tifxyz \
--volume predictions/w00_20231016151002_ink.ome.zarr \
--group-idx 0 \
--scale 1 \
--scale-segmentation 0.25 \
--segmentation /path/to/ink-dataset/phercparis4/w00_20231016151002 \
--num-slices 16 \
--slice-step 0.5 \
--cache-gb 16 \
--tif-output renders/w00_20231016151002_ink
This flattens the prediction into a stack of 16 slices spanning the surface, written as one TIFF per slice into the output folder. --scale-segmentation 0.25 maps the segment's full-resolution .tifxyz coordinates into the 4×-downsampled level-2 prediction volume. At that level, --slice-step 0.5 samples a focused band around the surface without accumulating as much papyrus texture as a wider step; use --slice-step 1 if you need to search farther along the normal. --scale 1 preserves the flat grid's output resolution. Finally, take a maximum over the slices to get a single readable image:
uv run --with numpy --with tifffile --with imagecodecs python -c "
import glob, numpy as np, tifffile
stack = np.stack([tifffile.imread(p) for p in sorted(glob.glob('renders/w00_20231016151002_ink/*.tif'))])
tifffile.imwrite('renders/w00_20231016151002_ink_max.tif', stack.max(axis=0))
"
The model trained on a single segment, so the interesting test is a segment it has never seen. Here are the same two checkpoints rendered this way on the central region of w05_4424, elsewhere in the scroll:


The run above is a starting point. For better results, give the trainer more segments and train longer; the next section covers where to get them.
Scaling up: the full dataset
Everything above ran on one segment; scaling up is mostly a matter of downloading more. Sync a whole scroll (or several) into the same folder:
uvx --from huggingface_hub hf buckets sync hf://buckets/scrollprize/datasets/ink/phercparis4 ./ink-dataset/phercparis4
The training config doesn't change — segments_path already points at the folder, and the trainer picks up every segment in it on the next run. More segments means more diverse training data, which is the single most reliable way to improve the model.
For inference across many segments, use folder mode — it runs the checkpoint on every segment in the folder and writes each prediction into a preds/ directory inside that segment:
uv run python -m koine_machines.inference.infer \
--folder /path/to/ink-dataset/phercparis4 \
--checkpoint-path runs/ink_tutorial/ckpt_020000.pth \
--batch-size 4
Improving the model: iterative labeling
A first model trained on a small dataset will reveal some letters clearly, others faintly, and miss some entirely. The way to make it better is the same loop that scaled ink detection to entire scrolls:
- Run inference on your training segments (and new, unlabeled ones).
- Inspect the predictions. Look for regions where letter strokes are clearly visible.
- Extend the labels. In those regions, paint the visible strokes white in the ink label image, and extend the supervision mask to cover the region — both the strokes and the clean background around them, since the background pixels are the negative examples the model learns from.
- Retrain on the enlarged labels, starting fresh or from your last checkpoint (add
"checkpoint": "runs/ink_tutorial/ckpt_020000.pth"and"weights_only": trueto the config). - Repeat.
Labels are ordinary image files, so you can edit them in any image editor that handles large images (e.g. GIMP or Photoshop). If you edit or create labels as TIFF/PNG files, convert them to the .zarr format the trainer expects with:
uv run python -m koine_machines.preprocessing.create_label_zarrs /path/to/ink-dataset/phercparis4
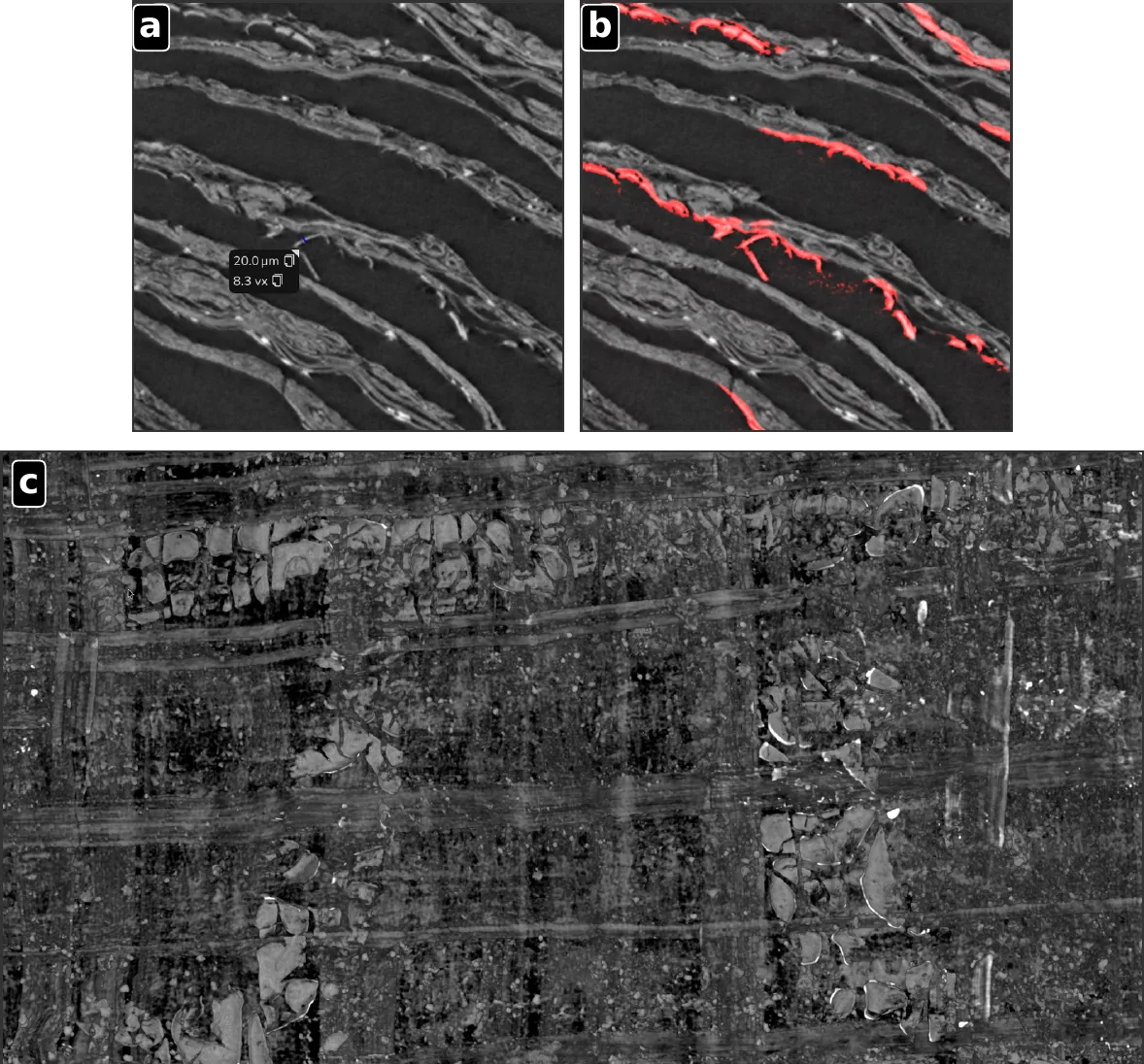
The figure below shows this loop in action on PHerc. 1667: with each iteration the labels (row a) grow from a handful of strokes to dense coverage, the model's predictions (row b) get cleaner, and the reading improves even on a held-out region that was never labeled (row c).

What's next
With segmentation and ink detection you now have the complete pipeline: from a 3D X-ray scan of an intact scroll to readable text. This exact loop — better segments, more careful labels, retrained models — is what produced the complete reading of PHerc. 1667, and there are hundreds of scrolls to go.
Join the Discord to see what the community is working on, check the open prizes, and help us read the rest of the library.